
‘The Future of the Past of the Web’
Digital Preservation Coalition Workshop
British Library, 7 October 2011
Chrissie Webb and Liz McCarthy
In his keynote address to this event – organised by the Digital Preservation Coalition , the Joint Information Systems Committee and the British Library – Herbert van der Sompel described the purpose of web archiving as combating the internet’s ‘perpetual now’. Stressing the importance to researchers of establishing the ‘temporal context’ of publications and information, he explained how the framework of his Memento Project uses a ‘timegate’ implemented via web plugins to show what a resource was like at a particular date in the past. There is a danger, however, that not enough is being archived to provide the temporal context; for instance, although DOIs provide stable documents, the resources they link to may disappear (‘link rot’).
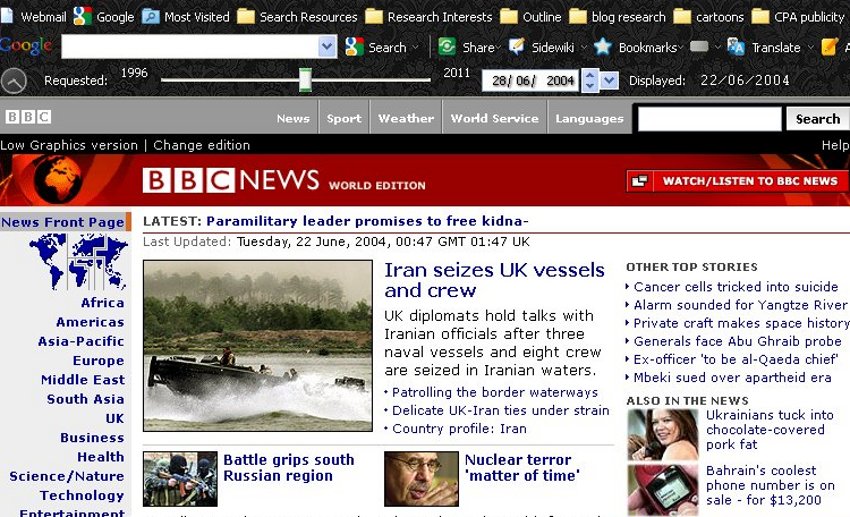 |
| The Memento Project Firefox plugin uses a sliding timeline (here, just below the Google search box) to let users choose an archived date |
A session on using web archives picked up on the theme of web continuity in a presentation by The National Archives on the UK Government Web Archive, where a redirection solution using open source software helps tackle the problems that occur when content is moved or removed and broken links result. Current projects are looking at secure web archiving, capturing internal (e.g. intranet) sources, social media capture and a semantic search tool that helps to tag ‘unstructured’ material. In a presentation that reinforced the reason for the day’s ‘use and impact’ theme, Eric Meyer of the Oxford Internet Institute wondered whether web archives were in danger of becoming the ‘dusty archives’ of the future, contrasting their lack of use with the mass digitisation of older records to make them accessible. Is this due to a lack of engagement with researchers, their lack of confidence with the material or the lingering feeling that a URL is not a ‘real’ source? Archivists need to interrupt the momentum of ‘learned’ academic behaviour, engaging researchers with new online material and developing archival resources in ways that are relevant to real research – for instance, by helping set up mechanisms for researchers to trigger archiving activity around events or interests, or making more use of server logs to help them understand use of content and web traffic.
One of the themes of the second session on emerging trends was the shift from a ‘page by page’ approach to the concept of ‘data mining’ and large scale data analysis. Some of the work being done in this area is key to addressing the concerns of Eric Meyer’s presentation; it has meant working with researchers to determine what kinds and sources of data they could really use in their work. Representatives of the UK Web Archive and the Internet Archive described their innovations in this field, including visualisation and interactive tools. Archiving social networks was also a major theme, and Wim Peters outlined the challenges of the ARCOMEM project, a collaboration between Sheffield and Hanover Universities that is tackling the problems of archiving ‘community memory’ through the social web, confronting extremely diverse and volatile content of varying quality for which future demand is uncertain. Richard Davis of the University of London Computer Centre spoke about the BlogForever project, a multi-partner initiative to preserve blogs, while Mark Williamson of Hanzo Archives spoke about web archiving from a commercial perspective, noting that companies are very interested in preserving the research opportunities online information offers.
The final panel session raised the issue of the changing face of the internet, as blogs replace personal websites and social media rather than discrete pages are used to create records of events. The notion of ‘web pages’ may eventually disappear, and web archivists must be prepared to manage the dispersed data that will take (and is taking) their place. Other points discussed included the need for advocacy and better articulation of the demand for web archiving (proposed campaign: ‘Preserve!: Are you saving your digital stuff?’), duplication and deduplication of content, the use of automated selection for archiving and the question of standards.