From the 14th – 16th of June researchers and practitioners from a global community came together for a series of talks, presentations and workshops on the subject of Web Archiving at the IIPC Web Archiving Conference. This event coincided with Web Archiving Week 2017, a week long event running from 12th – 16th June hosted by the British Library and the School of Advance Study
I was lucky enough to attend the conference on the 15th June with a fellow trainee digital archivist and listen to some thoughtful, engaging and challenging talks.
The day started with a plenary in which John Sheridan, Digital Director of the National Archives, spoke about the work of the National Archives and the challenges and approaches to Web Archiving they have taken. The National Archives is principally the archive of the government, it allows us to see what the state saw through the state’s eyes. Archiving government websites is a crucial part of this record keeping as we move further into the digital age where records are increasingly born-digital. A number of points were made which highlighted the motivations behind web archiving at the National Archives.
- They care about the records that government are publishing and their primary function is to preserve the records
- Accountability for government services online or information they publish
- Capturing both the context and content
By preserving what the government publishes online it can be held accountable, accountability is one aspect that demonstrates the inherent value of archiving the web. You can find a great blog post on accountability and digital services by Richard Pope in this link. http://blog.memespring.co.uk/2016/11/23/oscon-2016/
The published records and content on the internet provides valuable and crucial context for the records that are unpublished, it links the backstory and the published records. This allows for a greater understanding and analysis of the information and will be vital for researchers and historians now and into the future.
Quality assurance is a high priority at the National Archives. By having a narrow focus of crawling, it has allowed for but also prompted a lot of effort to be directed into the quality of the archived material so it has a high fidelity in playback. To keep these high standards it can take weeks in order to have a really good in-depth crawl. Having a small curated collection it is an incentive to work harder on capture.
The users and their needs were also discussed as this often shapes the way the data is collected, packaged and delivered.
- Users want to substantiate a point. They use the archived sites for citation on Facebook or Twitter for example
- The need to cite for a writer or researcher
- Legal – What was the government stance or law at the time of my clients case
- Researchers needs – This was highlighted as an area where improvements can be made
- Government itself are using the archives for information purposes
- Government websites requesting crawls before their website closes – An example of this is the NHS website transferring to a GOV.UK site
The last part of the talk focused on the future of web archiving and how this might take shape at the National Archives. Web archiving is complex and at times chaotic. Traditional archiving standards have been placed upon it in an attempt to order the records. It was a natural evolution for information managers and archivists to use the existing knowledge, skills and standards to bring this information under control. This has resulted in difficulties in searching across web archives, describing the content and structuring the information. The nature of the internet and the way in which the information is created means that uncertainty has to inevitably be embraced. Digital Archiving could take the turn into the 2.0, the second generation and move away from the traditional standards and embrace new standards and concepts. One proposed method is the ICA Records in Context conceptual model. It proposes a multidimensional description with each ‘ thing ‘ having a unique description as opposed to the traditional unit of description (one size fits all). Instead of a single hierarchical fonds down approach, the Records in Context model uses a description that can be formed as a network or graph. The context of the fonds is broader, linking between other collections and records to give different perspectives and views. The records can be enriched this way and provide a fuller picture of the record/archive. The web produces content that is in a constant state of flux and a system of description that can grow and morph over time, creating new links and context would be a fruitful addition.
Visual Diagram of How the Records in Context Conceptual Model works
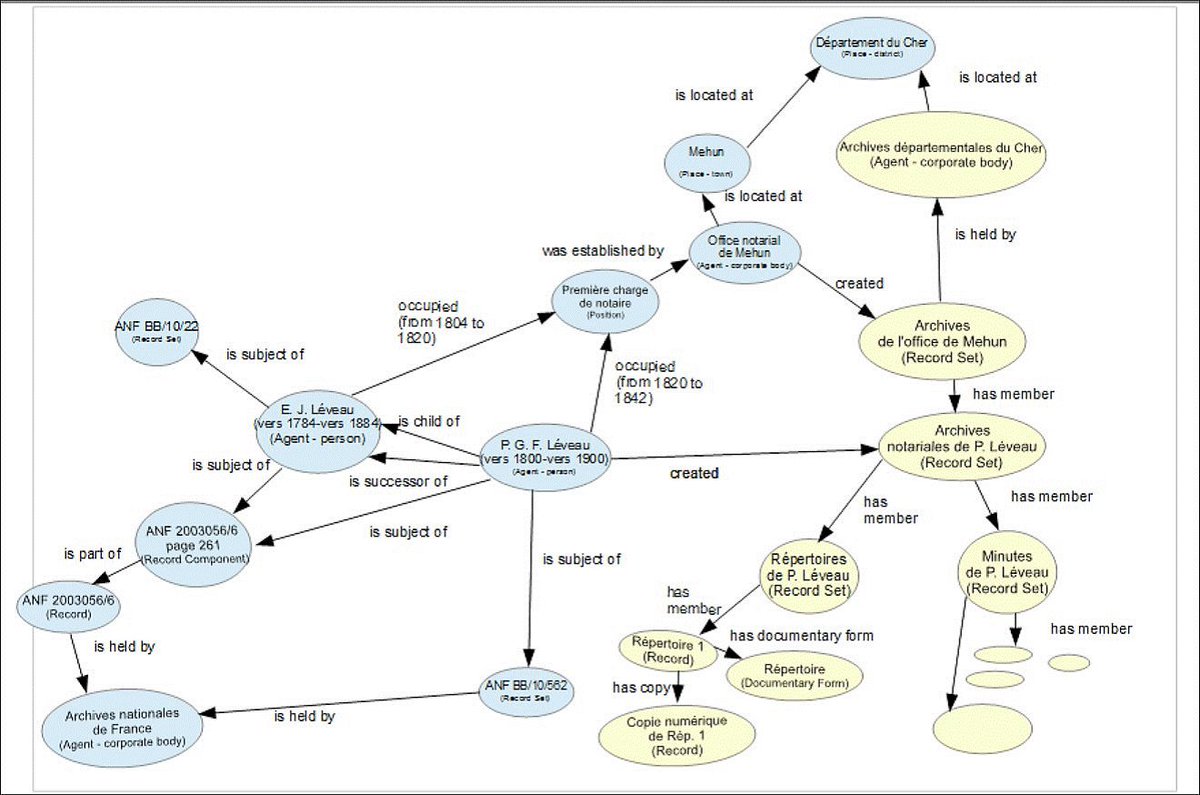
“This example shows some information about P.G.F. Leveau a French public notary in the 19th century including:
• data from the Archives nationales de France (ANF) (in blue); and
• data from a local archival institution, the Archives départementales du Cher (in yellow).” INTERNATIONAL COUNCIL ON ARCHIVES: RECORDS IN CONTEXTS A CONCEPTUAL MODEL FOR ARCHIVAL DESCRIPTION.p.93
Traditional Fonds Level Description

I really enjoyed the conference as a whole and the talk by John Sheridan. I learnt a lot about the National Archives approach to web archiving, the challenges and where the future of web archiving might go. I’m looking forward to taking this new knowledge and applying it to the web archiving work I do here at the Bodleian.
Changes are currently being made to the National Archives Web Archiving site and it will relaunch on the 1st July this year. Why don’t you go and check it out.