
The beginnings of the Online Enthusiast collection of the UK Web Archive can be traced back to November 2016 and a task to scope out the viability and write a proposal for two potential special collections with a focus on current web use: Mental Health, and Online Enthusiasts.
The Online Enthusiasts special collection was intended to show how people within the UK are using the internet to aid them in practising their hobbies, for example discussing their collections of objects or coordinating their bus spotting. If it was something a person could enthuse about and it was on the internet within the UK then it was in scope. Where many UK Web Archive Special Collections are centred on a specific event and online reactions, this was more an attempt to represent the way in which people are using the internet on an everyday basis.
The first step toward a proposal was to assess the viability of the collection, and this meant searching out any potential online enthusiast sites to judge whether this collection would have enough content hosted within the UK to validate its existence. As it turns out, UK hobbyists are very active in their online communities and finding enough content was, if anything, the opposite of an issue. Difficulty came with trying to accurately represent the sheer scope of content available – it’s difficult to google something that you weren’t aware existed 5 minutes ago. After an afternoon among the forums and blogs of ferry spotters, stamp collectors, homebrewers, yarn-bombers, coffee enthusiasts and postbox seekers, there was enough proof of content to complete the initial proposal stating that a collection displaying the myriad uses hobbyists in the UK have for the internet is not only viable but also worthwhile. Eventually that proposal was accepted and the Online Enthusiast collection was born.

The UKWA Online Enthusiast Communities in the UK collection provides a unique cultural insight into how communities interact in digital spheres. It shows that with the power of the internet people with similar unique hobbies and interests can connect and share and enthuse about their favourite hobbies. Many of these communities grow and shrink at rapid paces and therefore many years of content can be lost if a website is no longer hosted.
With the amount of content on the internet, finding websites had a domino effect, where one site would link to another site for a similar enthusiast community, or we would find lists including hobbies we’d never even considered before. This meant that before long we had a wealth of content that we realised would need categorising. Our main approach to categorising the content was along thematic lines. After identifying what we were dealing with, we created a number of sub-collections, examples of which include: Animal related hobbies, collecting focused hobbies, observation hobbies, and sports.
The approach to selecting content for the collection was mainly focused around identifying UK-centric hobbies and using various search terms to identify active communities. The majority of these communities were forums. These forums provided enthusiasts with a platform to discuss various topics related to their hobbies whilst also providing the opportunity for them to share other forms of media such as video, audio and photographic content. Other platforms such as blogs and other websites were also collected, the blogs often focused on submitting content to the blog owner who would then filter and post related content to the community.
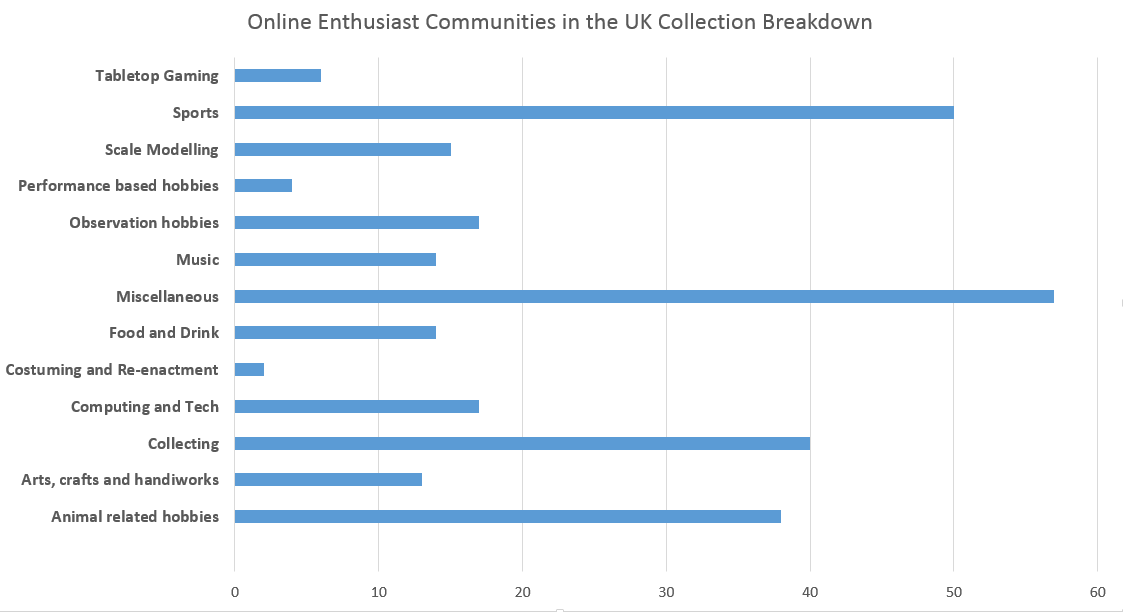
As of May 2018 the collection has over 300 archived websites. We found that the most filled categories for hobbies were Sports, collecting and animal related hobbies.
A few examples of websites related to hobbies that were new to us include:
- UK Pidgeon Racing Forum: An online enthusiast forum concerned with pigeon racing.
- Fighting Robots Association Forum: An online enthusiast forum for those involved with the creation of fighting robots.
- Wetherspoon’s Carpets (Tumblr): A Tumblr blog concerned with taking photographs of the unique carpets inside the Wetherspoon’s chain of pubs across the UK.
- Mine Exploration and History Forum: An online enthusiast community concerned with mine exploration in the UK.
- Chinese Scooter Club Forum: An online enthusiast community concerned with all things related to Chinese scooters.
- Knit The City (now Whodunnknit): A website belonging to a graffiti-knitter/yarnbomber from the UK
The Online Enthusiast Communities in the UK collection is accessible via the UK Web Archive’s new beta interface









_005.jpg){kind=link}