
We have a list of names of things, plus some idea of what type of things they are, and we want to integrate them into a database. I have been working on place names in Chinese, but it could just as well have been a list of author names in Arabic. This post reports on a procedure to get Wikidata identifiers — and thereby lots of other useful information — about the things in the list.
To recap a couple of problems with names covered in a previous post:
- Things share names. As covered previously, “cancer” names a disease, a constellation, an academic journal, a taxonomic term for crab, an astrological sign and a death metal band.
- Things have multiple names. One place is known to English speakers as “Beijing”, “Peking” or as “Peiping”. Similarly, there are multiple names for that place even within a single variant of Chinese.
There are some problems specific to historic names for places in China:
- The same name is often used, with different modifiers, for different administrative levels; a region, its capital city, and a district, for example. Hence there will be multiple entries in modern databases potentially corresponding to a “named” historic place. This means we are not looking for an exact name match: a two-character name in the source catalogue will connect to a three-character name in Wikidata.
- Modern Chinese words use a simplified orthography compared to historic Chinese.
- I’m a complete novice, not knowing one Chinese character from another.
Mix’n’Match
A general tool for this sort of problem is Magnus Manske’s Mix’n’Match. It takes an identifier, name, description and URL for each item in a catalogue, pairs it up with the closest name match(es) from Wikidata, then presents the pairs to human users to confirm or reject.

Descriptions from China Biographical Database and their matches on Wikidata (click to expand)
Among the catalogues fully matched on this system are many political databases such as Hansard, with 14 thousand individuals. Several hundred more catalogues are being matched by a gradual process of crowdsourcing, including the China Biographical Database (CBDB).

China Biographical Database, and some other catalogues, in the process of being reconciled in Mix’n’Match (click to expand)
Matching on names
In the present task we have just a name, not a URL or description. So we cannot use Mix’n’Match but we can find other ways to use the same algorithm, which boils down to three steps:
- Use a search to get a possible match in Wikidata.
- Extract some properties of the matched Wikidata item.
- Compare those properties against the properties of the source item, and accept or reject the match.
If we have different search processes, then the rejected matches from one search process can go into stage 1 of another.
This algorithm could be done in a dedicated piece of code or in the desktop application OpenRefine but I have been using Google Sheets. Google Sheets have an optional add-in, “Wikipedia and Wikidata tools” which makes it easy to call the Wikdata and Wikipedia APIs.
Pinyin transliteration
As a digression, another useful Google Sheets add-on is HanyuPinyinTools, which changes Chinese characters into their Pinyin version.
=HANYUPINYIN_TONEMARKS_ISO(A1)

These names aren’t necessarily useful for reconciliation with Wikidata, but they do give a non-Chinese speaker a view of what is going on. It’s a good sign when you are hoping for place names and phrases like “shang hai”, “bei jing” and “si chaun” appear.
Getting an initial match
One way to get a potential match would be to go to wikidata.org and paste the character string (say, “四川”) into the search box. That would bring up a list of potential matches — things known by that string or a very similar string — usually with English descriptions. Clicking on the most relevant-seeming match would bring up the Wikidata record and we could read that for further data such as a person’s birth or death years. Essentially we want to automate this process so it can happen thousands of times in parallel.
One option is to find the Wikidata identifier corresponding to the Chinese Wikipedia article with the title “四川”. To do this in Google Sheets we use:
=WIKIDATAQID(CONCAT("zh:",A1))
(“zh” being the code Chinese: for Arabic, it would be “ar”; for Hebrew “he” and so on. Cantonese would be “zh-yue”.)
This is gets a few matches, but the title of the Wikipedia article is only one of the Chinese names a place is known by, and the aforementioned issues with Chinese names mean that there is usually not a match. Even where there is a match, it might not be to an article but to a disambiguation page (those lists in Wikipedia of things with a similar name).
We could write a SPARQL query for the Wikidata Query Service to compare our Chinese characters to names and aliases, but here’s an obscure short-cut/ improvement. The query below combines the Wikidata Query Service and Wikidata’s site search function.
SELECT ?item (COUNT(?sitelink) AS ?sites) WHERE {
SERVICE wikibase:mwapi {
bd:serviceParam wikibase:api "EntitySearch" .
bd:serviceParam wikibase:endpoint "www.wikidata.org" .
bd:serviceParam mwapi:search "四川" .
bd:serviceParam mwapi:language "zh-hant" .
?item wikibase:apiOutputItem mwapi:item
}
?sitelink schema:about ?item
MINUS {?item wdt:P31 wd:Q4167410}
} GROUP BY ?item ORDER BY DESC(?sites) LIMIT 1
The language code “zh-hant” prioritises the traditional form of Chinese over the modern version.
The result this returns is, of the Wikidata entities known by the string 四川 or by a name starting with that string, the one with the most Wikipedia articles. This gives (roughly) the best-known or most-written-about thing with that name. In this particular case the result is Q19770, known in English as Sichaun, the province of China. The MINUS command removes disambiguation pages.
How to repeat this query automatically for large numbers of Chinese names? We will make calls to the query service over the web, so the whole query needs to be encoded as a URI, and the query has to be told to return XML so we have the result in a machine-readable format. Then Google Sheet’s IMPORTXML function will retrieve the result. To paste our Chinese characters into this string, we need to URL-encode them. I use the Javascript encodeURI() function, which I’ve customised my Google Sheets to use.
H1 =encode(A1)
Then we need to paste the encoded Chinese name into the URL-encoded version of the above query.
I1 =CONCATENATE("https://query.wikidata.org/sparql?query=SELECT%20%3Fitem%20%20(COUNT(%3Fsitelink)%20AS%20%3Fsites)%20WHERE%20%7B%0A%20%20SERVICE%20wikibase%3Amwapi%20%7B%0A%20%20%20%20%20%20bd%3AserviceParam%20wikibase%3Aapi%20%22EntitySearch%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20wikibase%3Aendpoint%20%22www.wikidata.org%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20mwapi%3Asearch%20%22", H1, "%22%20.%0A%20%20%20%20%20%20bd%3AserviceParam%20mwapi%3Alanguage%20%22zh%22%20.%0A%20%20%20%20%20%20%3Fitem%20wikibase%3AapiOutputItem%20mwapi%3Aitem%0A%20%20%7D%0A%20%20%3Fsitelink%20schema%3Aabout%20%3Fitem%0AMINUS%20%7B%3Fitem%20wdt%3AP31%20wd%3AQ4167410%7D%0A%7D%20GROUP%20BY%20%3Fitem%20ORDER%20BY%20DESC(%3Fsites)%20LIMIT%201")
Using the initial match
The returned XML will have one Q number (Wikidata identifier) in it, so we just need a regular expression to extract it.
J1 =REGEXEXTRACT(IMPORTXML(I1, "/"),"Q\d+")
So the procedure so far gets us the Wikidata identifiers of the most likely matches.
There are commands to get an English label and description for the Wikidata entity if they are available.
K1 =WIKIDATALABELS(J1,"en")
M1 =WIKIDATADESCRIPTIONS(J1,"en")

The description gives us one kind of check on the possible match. We can see that the Wikidata items returned represent places. There are various ways to get a more rigorous check. We can request the property P31 “instance of”. We can ask for property P625 “co-ordinate location”: not all locations will have this, but any item that has it is definitely a location. We can use the spreadsheet to separate out confirmed matches, candidate matches and failed matches.
Using the matches
A match with Wikidata entails a match with all the other databases and authority files that are linked from Wikidata. For British people, we might want their biographies in the Oxford Dictionary of National Biography. For authors we may well want VIAF (Virtual International Authority File) identifiers. For places, it would be nice to have the GeoNames ID. GeoNames ID is Wikidata property P1566, and Google Sheets can request this like so:
M1 =WIKIDATAFACTS(J1,"first","P1566")
Out of 92 names matched, 76 have a GeoNames ID in Wikidata.
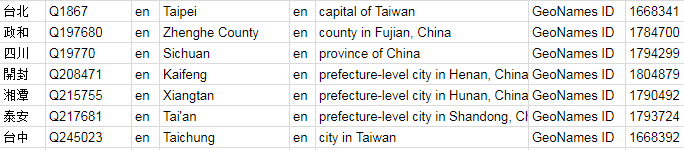
GeoNames IDs generated for most of the matched places
Another way to get an individual property is with an encoded SPARQL query. For instance, to get the VIAF (P214) of a person we can paste their Q number into another pre-defined Wikidata query.
M1 =CONCATENATE("https://query.wikidata.org/sparql?query=select%20%3Fv%20WHERE%20%7B%0Awd%3A",J1,"%20wdt%3AP214%20%3Fv%0A%20%20%7D%20LIMIT%201")
N1 =IMPORTXML(M1, "/")
Note: the documentation for Google Sheets suggests that some processing is needed to extract the value from the XML, but in my experience the value that appears is just the text content of the XML, which actually saves a step.
—Martin Poulter, Wikimedian in Residence
Thanks to Joshua Seufert, HD Chung Chinese Studies Librarian at the Bodleian Library, for help with some basic orientation around Chinese names.