
 As a participant in Emma Huber’s[1] inaugural Digital Editions course, I created a digital edition and accompanying transcription of a primary text held by the Taylor Institution Library. I chose to digitize, transcribe and encode a ‘mazarinade,’ dating from 1649 (title-page featured above). This piece belongs to the Taylorian’s vast collection of ‘mazarinades,’ or political pamphlets consisting of ‘short satirical or burlesque texts, in verse or prose, about Cardinal Mazarin, written at the time of the Fronde (1648-1653), a time of uprising and revolt in France while King Louis XIV was still a minor.’ The mazarinades satirize Cardinal Mazarin, who succeeded Richelieu as Minister of State and were the propagandist arm of the political revolution against the French Crown. The reasoning behind my choice of material was grounded in the pamphlet’s convenience for digitization, or ‘digitizability’: it is quarto-sized which means it is easy to photograph, legibly printed, which made it accessible to transcribe, and relatively short, making it a convenient choice for a contained project and first attempt at creating a digital edition. Furthermore, the Taylor Institution Library holds a large number of mazarinades that are not individually catalogued. I hope that the digital edition of the ‘Covrier de la Covr’ is a small contribution to the ongoing project to digitize them to raise awareness of their existence, improve access and, subsequently, promote their incorporation into research on early modern French history, literature and culture.
As a participant in Emma Huber’s[1] inaugural Digital Editions course, I created a digital edition and accompanying transcription of a primary text held by the Taylor Institution Library. I chose to digitize, transcribe and encode a ‘mazarinade,’ dating from 1649 (title-page featured above). This piece belongs to the Taylorian’s vast collection of ‘mazarinades,’ or political pamphlets consisting of ‘short satirical or burlesque texts, in verse or prose, about Cardinal Mazarin, written at the time of the Fronde (1648-1653), a time of uprising and revolt in France while King Louis XIV was still a minor.’ The mazarinades satirize Cardinal Mazarin, who succeeded Richelieu as Minister of State and were the propagandist arm of the political revolution against the French Crown. The reasoning behind my choice of material was grounded in the pamphlet’s convenience for digitization, or ‘digitizability’: it is quarto-sized which means it is easy to photograph, legibly printed, which made it accessible to transcribe, and relatively short, making it a convenient choice for a contained project and first attempt at creating a digital edition. Furthermore, the Taylor Institution Library holds a large number of mazarinades that are not individually catalogued. I hope that the digital edition of the ‘Covrier de la Covr’ is a small contribution to the ongoing project to digitize them to raise awareness of their existence, improve access and, subsequently, promote their incorporation into research on early modern French history, literature and culture.
As a graduate student in early modern French literature, I was equally as curious about the medium of the pamphlet as I was about creating a digital edition; the mazarinades are explicitly polemical products, designed to undermine the Crown’s authority but simultaneously written in verse and therefore perhaps also blurring the line between art and politics. On a theoretical level, I was intrigued by the parallelism between the pamphlet and the digital edition, both being media designed for mass dissemination. By imitating the process of textual editing implicit in the mazarinade’s original creation in the re-production of the pamphlet as a digital artefact, I was made aware of the intricacies undergirding such production in the first place.
This mazarinade is written in rhyming couplets, the playful, sing-song nature of which lends itself well to ridiculing the Cardinal and the Queen. It tells the story of the French court under attack by Spanish forces. The courier who arrives tells the Queen that the only way to save the country is to get rid of the insolent ‘ministre de France,’ who flees the country by the end of the poem. When Mazarin informs the king of his decision, the latter promptly ‘se prit a rire/Disant c’est que ie desire. [began to laugh/saying “that’s what I desire.”]’ further undermining Mazarin’s authority. What follows in the rest of this blog post is devoted to the process of creating this digital edition for those who want to learn more, but if you’re curious about the text itself, check it out here!
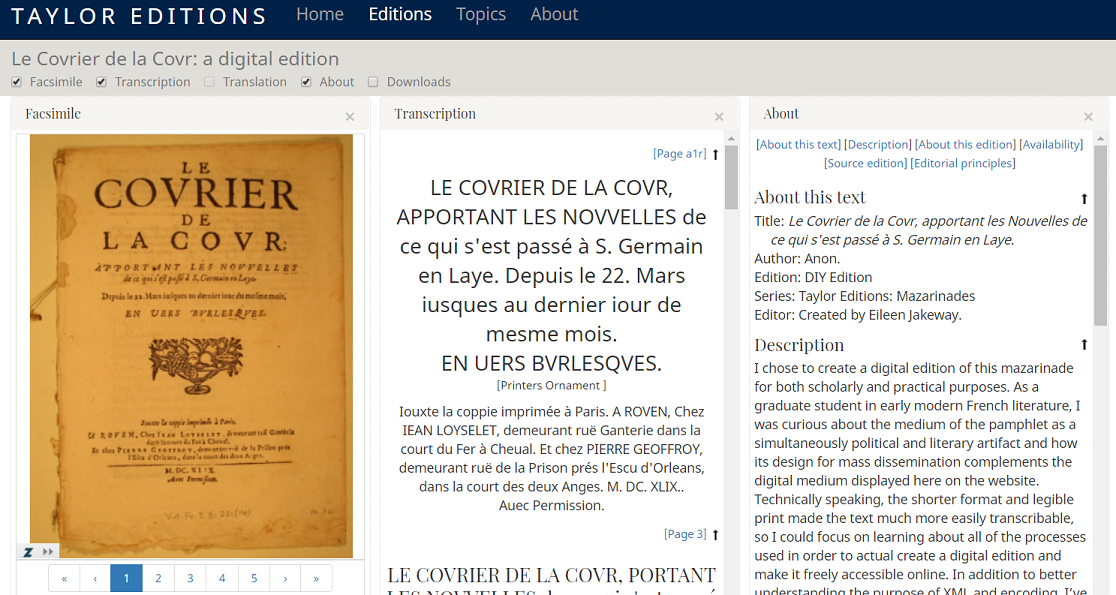
In the creation of this digital edition, editorial decisions began with the act of digitization itself. Under the guidance of Emma Huber, I learned about the various processes behind the creation of a digital edition, a process starting with digitization. In this case, the analog paper pamphlet was turned into a digital document by capturing its image. We used the Library’s camera to photograph each page of the mazarinade, which could be easily saved and transferred to our computers. Already at this stage, the bias of the editor/digitizer crept in, for I initially had not photographed the blank back-side of the pamphlet’s cover page. It contained no information I thought was valuable. And yet, this editorial decision resulted in an incomplete, bastardized version of the pamphlet that, though it was a digital facsimile, was already different from the original. Lots of factors went into the taking of these images such as the care of the book, making sure not to overextend the edges, using lead snakes to hold the pages down, natural lighting and using the maximum resolution possible on the camera.
Once we had all the images, we needed to ‘compress’ the images so that they could be easily represented as thumbnails on the digital editions website; Emma walked us through the various available formats and their purposes. We learned to use the TIFF format for our master images as it is the large preservation format. PNG files compress the file, but don’t lose any data in the process—which is why it can be called ‘lossless’ compression. The reason for not using a .jpeg file is because it creates a small file but loses data every time the file is saved (lossy compression). After converting the images to TIFF files then we cropped them to a standard format that makes the image easily viewable. Emma emphasized the importance of always retaining the original image and saving any changes made as a separate file. The importance of this is to ensure that no data is lost, since with every new save and/or change you lose information about the original image. She also emphasized the importance of providing metadata about the images such as which camera was used, the resolution, date of the picture, the shelfmark of the document captured, the holding library and then a description of the content of the image. This metadata should always be in open format that is available to anyone. And the description should use a controlled vocabulary in order to describe the content of the image so that it is more easily searchable for interested viewers.
It should be noted here that using a camera for the creation of digital text is useful when wanting to display that text alongside a transcription, but since cameras are unable to perform Optical Character Recognition (OCR), these digital documents alone are often insufficient for researchers, as they are not searchable or in a format that can be manipulated into other formats. As such, transcription was an essential component of this project; I chose to create a semi-diplomatic transcription, which attempts to preserve as much of the original textual presentation as possible, except where making small orthographic changes greatly enhances the readability for a modern audience. In my edition, all original spelling has been maintained, including the interchangeable use of u and v and other spelling variations. All accents and original punctuation have been reproduced, although editorial choices about spacing were made; where I felt the original lack of spacing between words would have made the document less readable or unclear, I used modern spacing practices. On line 210, there appears to be a printer error: it reads “lny” instead of “luy” however I maintained the mistake as such and signalled it in my editorial note.

Our transcriptions were created in the oXygen text editing software application, which creates ‘plain text’ that conforms easily to the XML markup language and thus also lends itself more easily to the process of ‘encoding.’ During this process, we also learned about the Text Encoding Initiative (TEI) which has set out the rules for various elements used by XML to encode a transcribed text. These various codes and tags not only delineate the format elements, such as the title, body, quote, but also where verse appears and where editorial choices have been made. By doing this ‘structural encoding,’ it makes it possible for the encoded text to serve as the base for a variety of ‘transformations,’ in which the XML document is transformed into HTML (webpages), a PDF, EPUB (e-publication), DOCx or ODT (open data document). For me, the most important implication of having an xml-encoded text is that it opens up the possibilities of where you can take the scholarship from there. Although I did not extend the project this term, I would have been able to extract much data from a set of mazarinades. Hopefully when the corpus of digital mazarinades grows, scholars will be able to query the data sets using methods such as content analysis, social network analysis and corpus linguistics in order to expand the research being done on these texts. By turning qualitative observations into quantitative data, it might be possible to reach more audiences with more information. For example, now that I have the XML version, I could create a visualization that tracks the number of times the Queen regent is mentioned in the mazarinades, compared with how many times Cardinal Mazarin occurs, and compared with how often their names are mentioned in conjunction. I would have to ‘code’ the occurrences of each of these incidents, but once I have the quantitative data, I could use data visualization tools to present this information clearly and succinctly on a visual graphic.
While this seems to be a bit superfluous and redundant for a short pamphlet that can easily be studied by a literary scholar, the potential for data visualizations is particularly useful to researchers looking at massive corpora of texts, because it allows them to look at the information from a distance in a way that might lead to new research questions. And secondly, this merging of quantitative methods and qualitative data in sources such as literary texts, makes the research more easily accessible to a lay audience. Rather than needing to possess the skills of an Oxford graduate student, information can be communicated effectively in a matter of minutes with a good visualization and a thorough legend for the graphic. Therefore, the creation of digital editions is significant not only because they break open access to documents by making texts freely available online, but because the creation of ‘metadata’ about the texts and the quantification of humanities-based observations gives rise to different kinds of research methodologies that ask different kinds of questions; not only does this give the humanities researcher more breadth to contextualize and deepen her own research, it also provides the space for interdisciplinary collaboration on textual or historical artefacts that become the point of convergence for researchers from fields ranging from comparative literature to anthropology to computer science. Such collaboration inevitably results in, or has the capacity to result in, a deeper understanding not only of historical narratives and literary methods, but also of the socio-political structures governing access to information and its distribution in the modern day.
For me personally, the digitization of this mazarinade allowed me to connect to the text and the conditions of its original production that would not have been apparent had I been studying it online as an already digitized document. Going through the entire process of creating the digital document, its text and its context, as well as publishing it online for a variety of audiences brought to mind questions about the various layers of decision-making behind the creation of a text by a multitude of actors, from the author to the editor to the printer and the distributor. Although these questions would arise with any digital edition, the choice of the mazarinade aligned well with this one, especially when thinking about the polemical and ethical dimensions of mass textual dissemination. It is my hope that this blog post will serve as a small means of contextualizing the creation of this digital edition and prompt readers—researchers, teachers, students, historians, librarians, mazarinade enthusiasts alike—to think about how we acquire, process, and package information in the modern age and whether or not universities and libraries, as major guardians of this information, have an ethical responsibility to disseminate it so that texts, like the mazarinades, that were intended for a public readership, can reach one in the modern day.
[1] Emma Huber is the German subject librarian at the Taylor Institution Library, Oxford.
………………………………….
Eileen Jakeway, MSt French and German