Web archiving is a relatively new initiative which is becoming more and more of a priority as we realise how rapidly the World Wide Web is expanding and how transient web pages can be. The Bodleian Libraries is working to ensure meaningful online content is captured for posterity and future research.
The British Library’s UK Web Archive blog published a worrying chart of how many URLs are now irrecoverable because the content is simply no longer available online:
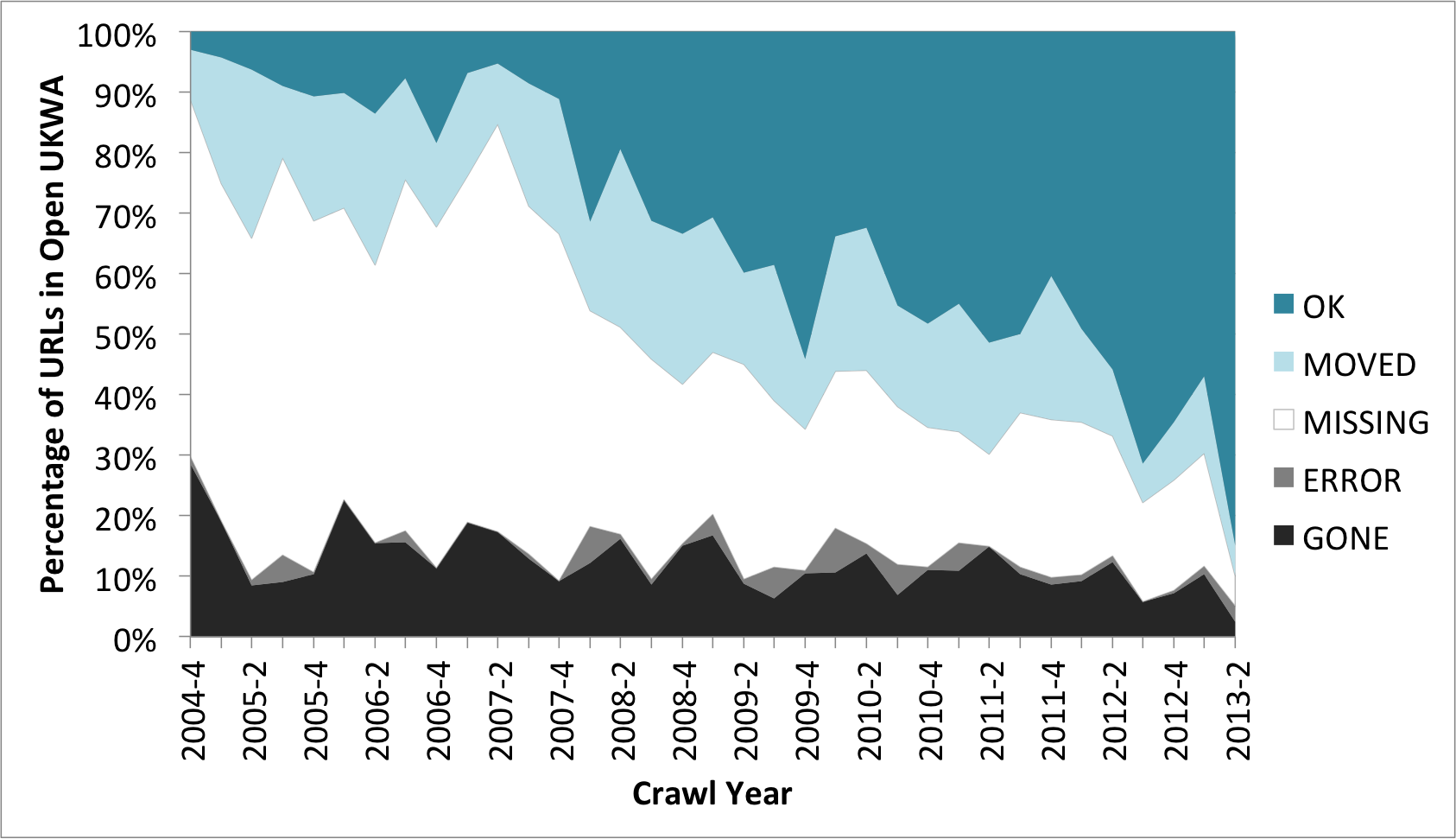
(‘What is still on the web after 10 years of archiving?’, UK Web Archive Blog, 2014)
To combat this in the future, the Bodleian has been contributing to the British Library’s UK Web Archive, alongside the five other legal deposit libraries for the UK (the British Library, the National Library of Scotland, the National Library of Wales, Cambridge University Library, and the library of Trinity College Dublin). We do this by selecting sites to be archived and deciding how often snapshots of their content should be taken, which ranges from weekly to annually to just a one-off interactive picture of the site. The Bodleian has ensured the World Wide Web’s recording of significant global happenings has been captured by curating collections on the Ebola epidemic and Typhoon Haiyan. As well as this, the Bodleian contributes to collections managed by all the legal deposit libraries, such as the UK General Election and the Scottish Independence Referendum, and offers input into what sites should be considered key sites and crawled regularly. These cover a broad range of subjects, from news sites to governmental sites to sports sites, to ensure the strongest representation of society today is preserved.
As well as this initiative, the Bodleian has been developing its own web archive, which seeks to archive sites which relate to the University of Oxford, and to the Bodleian’s archival holdings. We are working hard to capture the websites of the various colleges, departments and sub-divisions which make up the university, as well as building web archive collections around the subjects of Arts and Humanities; International; Science, Medicine and Technology and Social Sciences to complement and strengthen our physical holdings. Sites include those relating to J.R.R. Tolkien, the Conservative Party and research sites on colonialism and the British Empire. We welcome public nominations for sites you deem worthy of perpetual preservation, and also invite the public to consult our current web archives. You can find links to both here.
Websites crawled in the UK Web Archive are produced in the United Kingdom and so can be crawled under the E-Legal deposit act. The Bodleian’s Web Archive, on the other hand, relies on gaining permission from the website owner to capture the website. If permission is granted, we add it to our collections, and set it to a One-Time, Monthly, Bi-monthly, Quarterly, Semiannual or Annual crawl, and the captures are available online after each time they are produced. The work does not stop there though, as websites are constantly updated, which means we need to check collection-crawls at determined intervals to make sure we are still preserving accessible content.
Since beginning the web archive in March 2011, we have captured a broad range of websites, and have accessible archives of content that is no longer available, such as the webpages for the Conservative Women’s Organisation for Yorkshire and the South West.
As well as preserving valuable transitory content, the web archive charts the development of websites. A screenshot of the Bodleian Libraries’ homepage captured in October 2011 in contrast to that taken in October 2015 demonstrates how much websites transform visually and aesthetically, as well as documenting their content changing.
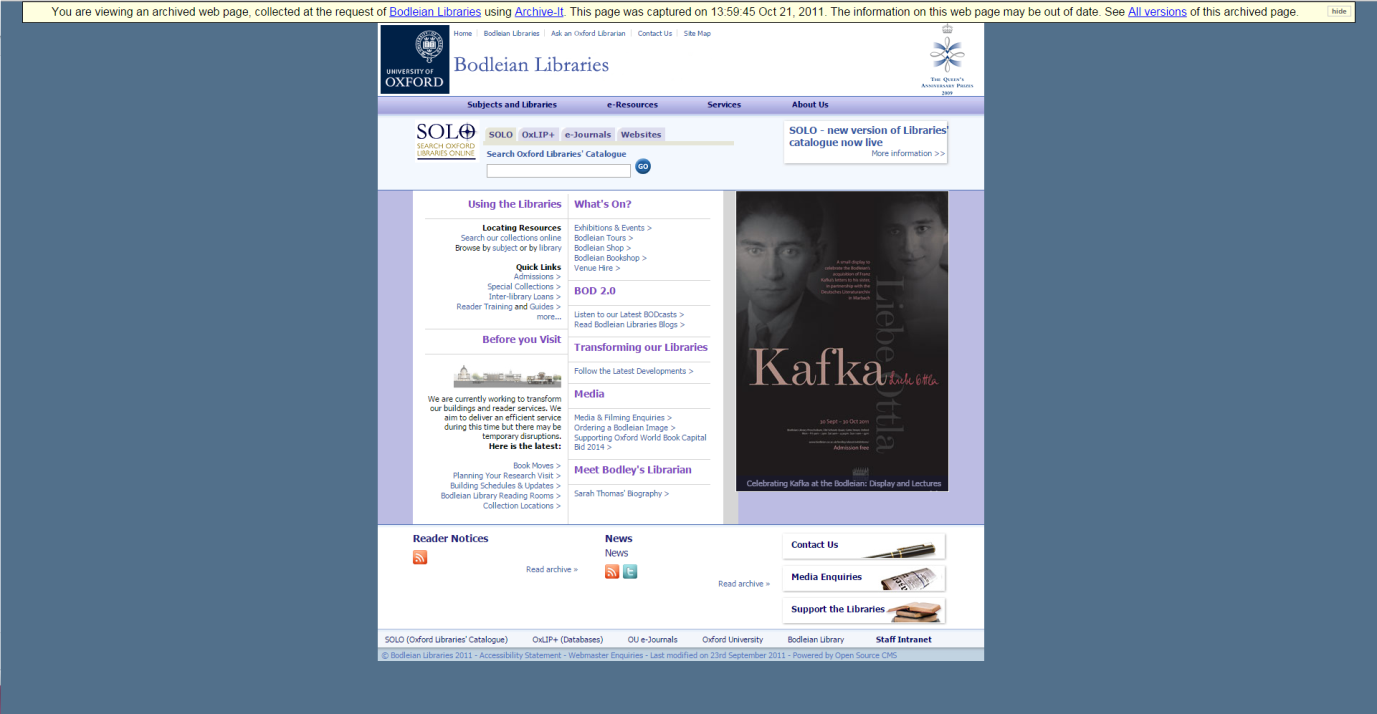
(capture of www.bodleian.ox.ac.uk, October 2011)

(capture of www.bodleian.ox.ac.uk, October 2015)
If you would like to learn more about using web archives as scholarly resources, there will be a free public lecture on the subject on the 11th December 2015. You can reserve tickets here.