
One of my earliest memories of television was James Burke’s series Connections. It was fascinating yet accessible: each episode explored technology, history, science and society, jumping across topics based on historical connections or charming coincidences. One episode started with the stone fireplace and ended with Concorde.
In a digital utopia, we would each be our own James Burke, creating and sharing intellectual journeys by following the connections that interest us. We are not there yet. Many very valuable databases exist online, but the connections between them are obscured rather than celebrated, and this is an obstacle for anyone using those data in education or research. In a previous post I described the problems that come from the fact that things have different names in different databases, and described a semantic web approach to link them together.
Building on this approach, web applications can help people create their own stories; choosing their own path through sources of reliable information, building unexpected connections. In this post I describe three design principles behind these applications. Let’s start with a story.
The Nanteos cup is a wooden bowl; one of hundreds of objects that has been claimed to be the Holy Grail. It is now in the collection of the National Library of Wales (NLW). The Nanteos was a merchant ship described in the Aberystwyth shipping records, also in the NLW collection. Both the cup and the ship are named after Nanteos mansion, a country house in mid-Wales. It has Grade 1 listed status and as such is described in heritage registers.
Rev William Powell was an 18th-century deacon. He is described in the Dictionary of Welsh Biography (DWB), whose online edition is hosted by the NLW. Nanteos mansion was the residence of his family, including William Edward Powell, who served for 45 years as a Member of Parliament during the early 19th century. Nanteos, co. Cardigan: the seat of W.E. Powell, Esq. M.P is a print in the Welsh Landscape Collection, also part of the NLW collections. This print, depicting the mansion and the surrounding countryside near Aberystwyth, was published by Stannard and Dixon in London.
Since the National Library of Wales has created Wikidata representations of the landscape prints, of the shipping register, and of the DWB, there is open data describing all these things and the relationships between them.
 (Image by Jason Evans, NLW. CC-0)
(Image by Jason Evans, NLW. CC-0)
Reasonator is an open source site that summarises all that Wikidata has on a topic. Go to its entry for the Nanteos mansion and we can see these connections to other entities. We can follow links to learn about the type of thing we are interested in (publishers, politicians, ships…), or follow external links to authoritative resources such as the DWB or the NLW catalogue.
Although landscape prints, a shipping register, a collection of archaeological finds and a biographical dictionary are distinct resources, they ultimately describe a shared reality. Creating a profile for Nanteos mansion was not an intended outcome of digitising and describing these sources: it is one of many profiles emerging when we represent those sources as open, semantically-linked data.
Reasonator and similar applications give us our first principle: the node. By this I mean a page that summarises what is known about a concept, usually in the form of links to other sources. Online databases already have pages summarising information about items; say, the individual items in a museum collection. With Wikidata, we can make nodes for a particular concept, which could be a historical person, a culture (such as the Song Dynasty), a technique (such as enamel-glazed pottery) or a location (such as Nanteos mansion).
A node about a particular era of ancient China would ideally point you towards art works from that era, towards photographs or diagrams of architecture from that era, and towards writings by or about the significant people of that era. A node about a mansion in Wales should link you to artworks that depict the building, notable objects found there, and biographies or portraits of the powerful family that lived there.
As far as possible, the node should point users towards specific information about the topic, not to another search box. A user who has reached the node about Nanteos mansion has already searched for a concept, and they should not be required to search again. This kind of design is possible if we make sure that the web link of each node consists of a stem plus an identifier. Here’s the Reasonator link again for Nanteos mansion:
https://tools.wmflabs.org/reasonator/?q=Q6964304
Note it’s just a stem followed by Wikidata’s identifier for the mansion.
The next component is the visualisation. This is an index of nodes, but in a more interesting form than a list. Nodes are going to be online and findable via search engines, but visualisations will direct people to nodes that share an interesting connection. Maps and timelines are good examples. For instance, thousands of person identifiers from Early Modern Letters Online have been added to Wikidata. Thus a Wikidata query can build links to individual entries in the EMLO database. I’ve asked Wikidata for people in EMLO who were members of the French Academy of Sciences, organised on a timeline by birth and death date. We can feed this query into HistropediaJS, a free service that renders Wikidata query results as gorgeous interactive timelines. Double-clicking an entry on the timeline takes you to the relevant page in EMLO.

Timeline of members of French Academy of Sciences, with links to EMLO.
We could just as easily links to nodes in some other system, so long as that system uses identifiers in its URLs. Here’s the same timeline but the links go to Reasonator. If we wanted to combine other biographical resources with EMLO, we could create nodes for each person, pointing to their EMLO records and their links in the other databases, then link from the timeline to those nodes.
One kind of front end that could be built for EMLO would give the user a menu of organisations or movements: the Royal Society, the Society of Antiquaries, and so on. Each link would take them to a Histropedia timeline of members of that organisation, and each link from the timeline would go the person’s EMLO record. This would be simple to create; essentially just a pair of database queries.
By modifying a query, we could give users some foreknowledge of what will happen when they click a link. For instance, next to each society we could show the number of EMLO people who were members of that society.
Crotos is a multilingual, Wikidata-driven site for exploring art works. Amongst other interfaces, it has a very nice global map where you can zoom in on a part of the world and view art works depicting that location. The entry for an individual work shows an image along with essential information such as the object’s collection and inventory number. The magic behind the scenes is that each web address for an art work ends with its Wikidata identifier, so the site queries Wikidata for that identifier, then presents the results in an attractive way.
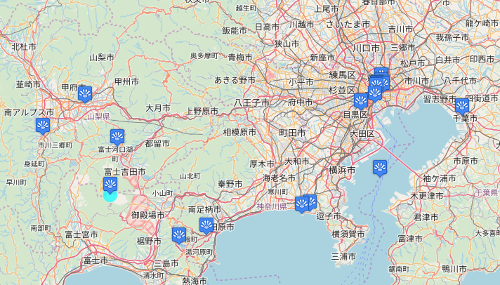
Locations in Japan that are depicted in art, via the Crotos/Callisto web application (using OpenStreetMap)
So far we have been looking at a tree-based view of resource discovery: a visualisation links to lots of nodes, and those nodes link directly to entries in a database or museum catalogue. The third step is to introduce many-to-many relations, so that each node acts as an index to other nodes and visualisations. Put more simply, make everything a link.
The BnF (national library of France) makes the text of many out-of-copyright books available through its Gallica site. Some Wikidata contributors have used this to build Textes d’Affiches, a site to explore films and the books they are based on. It takes film data from the Internet Movie Database (IMDB) and links from Gallica. Wikidata represents the films, the books, and the “based on” relations between them, so each page is essentially a prettified version of a Wikidata query, plus data from the other sources. Someone interested in the Hunchback of Notre Dame gets details and the full text of the Victor Hugo book. From Victor Hugo’s node they can also find Les Misérables and the films based on that. They can navigate between books via their authors, or between films via their directors. So users can find their own journeys, linking pop culture and classic literature.
The Wikidata-driven scholarly profiles site Scholia works a similar way: a link ending in /author/[a Wikidata identifier] will return a profile of the author with that Wikidata entry. Information about papers, awards and publishers are referenced similarly for /work/ /award/ and /publisher/ . These entities relate to each other in predictable ways: a paper has authors and is published in venue (such as a journal). A venue has a publisher and an editor; a publisher has a roster of journals; an award has winners and a sponsoring organisation. Scholia is a colourful way to explore millions of pieces of information but it’s a very small application. Essentially it is a group of well-constructed node-schemas each querying Wikidata about one kind of entity, making links to each other.
These sites exemplify the third design principle under discussion here: making a web. To recap, these sites generate nodes which provide access to everything a system knows about a given concept. Nodes are easily accessed using just an identifier. Visualisations, which can themselves be generated from data, connect one node (such as the French Academy of Sciences or Tintern Abbey) to a lot of other nodes (members of the Academy; paintings of the Abbey). Finally, there are several different kinds of nodes, each having its own visualisations and so pointing to nodes of different types.
I’ve queried Wikidata for things associated with a Chinese dynasty (or Ancient China) that are in a present-day museum collection (some interesting fields are left out for the sake of space). There are only a few dozen records now but in the longer term there could be very many. The raw results from Wikidata are in the form of a table. We could prettify them in various ways, but using the principles described here we could create one set of concept nodes for Han dynasty, Sui dynasty, Tang dynasty and so on; another set of nodes for the collections that the objects are part of, and other nodes for types of object, or for materials and techniques. Finally, we’d make the nodes point to each other, so that from a material we could see which periods of ancient china it was associated with, and get a list of objects, while from the node for a particular dynasty we would get the associated materials, objects and collections.

Burmese musical instruments via Digital Bodleian and Wikimedia Commons, CC-BY
Musical instruments might be another theme that can be visualised across collections at Oxford. Not just because of the dedicated museum of musical instruments, but because the topic arises in other collections. The Bodleian Library has a guitar (with a Wikidata representation). Flageolets and drums are depicted in a watercolour inside a set of 19th century Burmese manuscripts held by the Bodleian Library. “Boy with a flageolet” is an Italian painting in the collections of the Ashmolean Museum.
What are we missing out on by not sharing data in a way that fits into this semantic web approach?
- What entities do we lack nodes for, because their mere mentions seem unimportant until we link them together? A dedicated node for Nanteos mansion is more search-engine friendly than several large texts or databases, each of which give it a fleeting mention, and tools similar to Reasonator can bulk-create these nodes.
- What resources are users not finding because they cannot jump across sources: from the catalogue entry for an object to the biography of its owner; from a place to the artefacts discovered in that place?
- What apps are people not building because it is not practical to combine data from different sources (e.g. to locate properties owned by historical aristocratic families and the items housed there)?
—Martin Poulter, Wikimedian in Residence